
0. 들어가기전, 개념 소개 및 설치
웹 크롤링?
웹 상에 있는 원하는 정보를 수집
-> 스스로 데이터베이스 구축 가능 !!!
BeautifulSoup
소스코드를 파싱하는 데 사용하는 라이브러리
BeautifulSoup은 html에서 원하는 정보를 빠르게 찾을 수 있다.
! pip install beatifulsoup4
form bs4 import BeautifulSoup
BeautifulSoup 설치 후 requests 설치
url을 주면 html을 가지고 오는 모듈(urllib & requests)
! pip install requests
import requests
+ Selenium 과 BeautifulSoup 라이브러리 정리해뒀습니다.
https://rladuddms.tistory.com/64?category=921467
웹 크롤링) Selenium VS BeautifulSoup 라이브러리 비교
크롤링에는 대표적으로 두 가지 라이브러리를 사용한다. 차이를 알아보자. Selenium BeautifulSoup 웹 동작 html 정보 파싱 동적 크롤링을 효과적으로 수행 라이브러리 자체가 무겁고, 자주 막힌다 Reques
rladuddms.tistory.com
1. 네이버랩 실시간검색어 html 가지고 오기
정보를 가지고 올 url (네이버) 열기
네이버에 실시간 검색어에 필터가 생기면서 네이버 홈페이지에선 크롤링을 할 수 없게 되었습니다.
url = 'https://datalab.naver.com/keyword/realtimeList.naver'
네이버 데이터랩 : 급상승 검색어
검색 횟수가 급상승한 검색어의 순위를 다양한 옵션을 통해 자세히 제공합니다.
datalab.naver.com
크롤링이 막히는 경우를 방지하기 위한 방법
자동 프로그램을 사람처럼 위장하기 위한 user-id
1. headers
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_5) AppleWebKit 537.36 (KHTML, like Gecko) Chrome",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8"
}
2. import time
크롤링에 시간차를 두어 사람처럼 보이게 위장.
네이버 틀기도전에 코딩 실행하면 오류뜨니까 시간차이 두기.
html 불러오기 ★
1) requests를 통해 정해준 url에 정보를 요청. 그 정보를 response 변수에 저장한다.
response = requests.get(url, headers=headers)
2) url 정보가 들어있는 response의 텍스트 정보를 source 변수에 저장한다
source = response.text
source
-> 텍스트라서 어떤게 태그이고 속성이고 속성값인지 알 수 없다.
-> 그래서 파싱이 필요하다 !
3) html 파싱하기.
BeautifulSoup을 통해 'lxml'파서를 사용하여 soup에 html 정보를 저장한다.
파이썬에서 사용할 수 있는 의미있는 객체구조로 변환하는 과정이다.
soup = BeautifulSoup(source, 'lxml')
soup
4) html 코드 예쁘게 출력하기
soup.prettify
2. html 태그로 확인하기
html 태그 구조
- <태그 명(a, span, title, li...) 속성(class, content, href...)="속성 설명"> 텍스트 </태그>
html 확인하기
- F12 -> html 코드 보기
- 찾고자하는 부분에서 오른쪽 마우스 검사창 클릭 -> html 코드 중 찾아준다
태그로 첫번째 정보만 가져오기
soup.find('meta')
태그로 모든 정보 찾기
soup.find_all('meta')
태그와 속성 찾기. 리스트 형태로 반환
soup.find_all('a', attr = {'class' : 'nav'})
태그로 첫번째 텍스트 확인
soup.find_all('a', attrs = {'class' : 'nav'})[0].text
검색어 찾기! 전체연령 기준으로 나온다.
soup.find_all('span', attrs = {'class' : 'item_title'})
순위 찾기! 전체연령 기준으로 나온다.
soup.find_all('span', attrs = {'class' : 'item_num'})
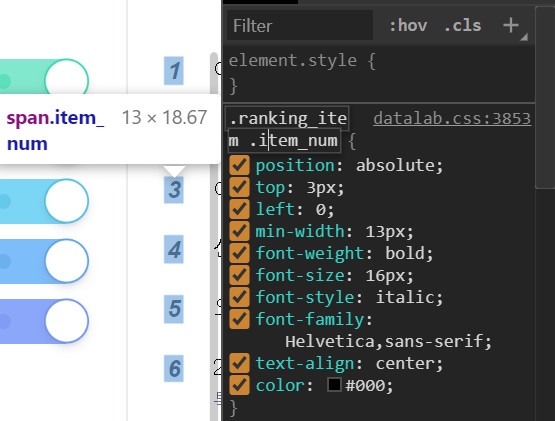
검색어 리스트 for문 만들기!
search_word_list = []
for i in range(0,20) :
rank = soup.find_all('span' , attrs = {'class' : 'item_num'})[i].text
search_word = soup.find_all('span', attrs = {'class' : 'item_title})[i].text
data = rank, search_word
search_word_list.append(data)
search_word_list #리스트 확인
search_word_list = search_word_list[:10] #10위까지만 저장하기
3. 파일 내보내기
데이터프레임으로 저장하기
import pandas as pd
df = pd.DataFrame(search_word_list, columns = ['순위', '검색어'])
df
for i in range(0,20) :
csv 파일로 내보내기
df.to_csv('네이버랩 실시간 검색어 순위.csv', encoding = 'utf-8')
4. 많이 실습해보기 ★★★
연습할겸, 네이버 인물정보 크롤링해봤습니다.
https://rladuddms.tistory.com/65
웹 크롤링) 네이버 인물정보 크롤링하기
웹 크롤링 혼자서 공부해봤습니다! 코드 공유합니다~ 네이버 인물정보 "재현"을 검색한 것을 url로 하여 앨범,공연 정보를 크롤링했습니다. BeautifulSoup을 활용했고, 아직 사진이랑 방송 정보는 크
rladuddms.tistory.com
'Stay Hungry Stay Foolish > 웹 크롤링' 카테고리의 다른 글
| 웹 크롤링) 네이버 인물정보 크롤링하기 (2) | 2021.02.10 |
|---|---|
| 웹 크롤링) Selenium VS BeautifulSoup 라이브러리 비교 (0) | 2021.02.10 |

댓글